Prilagajanje krivulje: definicija, metode in uporaba v statistiki
Prilagajanje krivulje: definicija, metode in uporaba v statistiki, praktični primeri interpolacije, glajenja, regresijske analize in ekstrapolacije za boljše napovedi
Prilagajanje krivulje je konstruiranje matematične funkcije, ki najbolje ustreza nizu podatkovnih točk.
Prilagajanje krivulje lahko vključuje interpolacijo ali glajenje. Interpolacija zahteva natančno prileganje podatkom. Pri glajenju se konstruira "gladka" funkcija, ki se približno prilega podatkom. Sorodna tema je regresijska analiza, ki se bolj osredotoča na vprašanja statističnega sklepanja, na primer koliko negotovosti je prisotne v krivulji, ki se prilega podatkom, opazovanim z naključnimi napakami.
Prilagojene krivulje lahko uporabimo za lažjo vizualizacijo podatkov, za ugibanje vrednosti funkcije, kadar ni na voljo podatkov, in za povzemanje odnosov med dvema ali več spremenljivkami. Ekstrapolacija se nanaša na uporabo prilagojene krivulje zunaj območja opazovanih podatkov. Pri tem je prisotna določena stopnja negotovosti, saj lahko odraža tako metodo, uporabljeno za konstruiranje krivulje, kot tudi opazovane podatke.
Galerija slik
3 Slike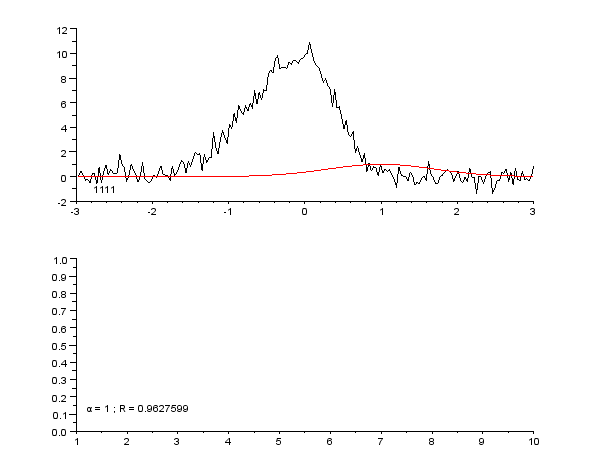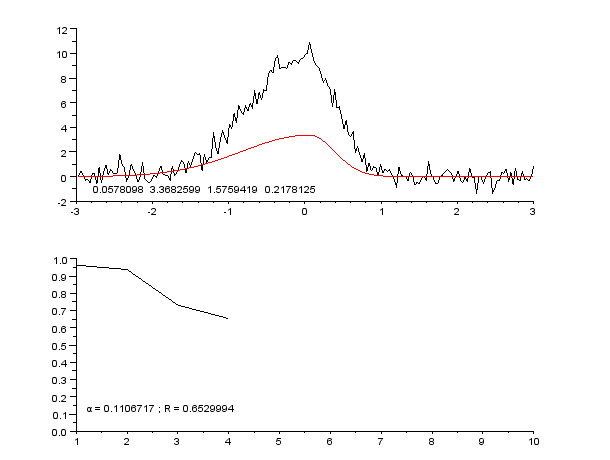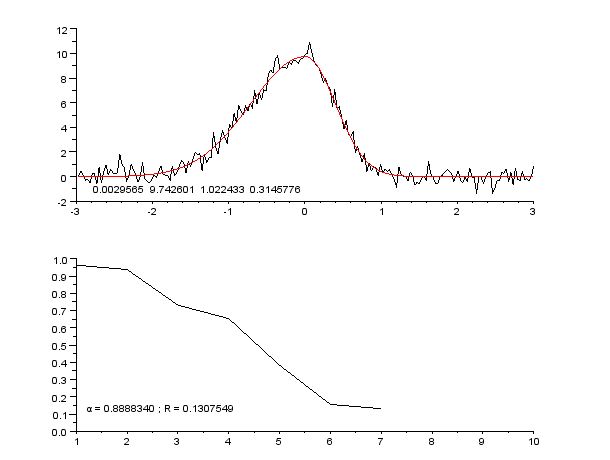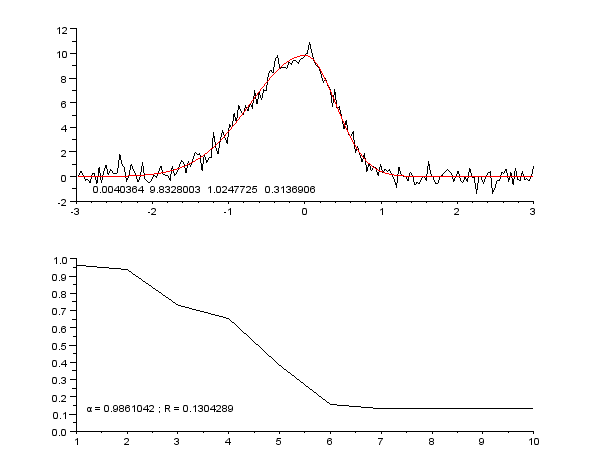


Metode prilagajanja krivulje
- Najmanjši kvadrati (OLS) — najpogosteje uporabljena metoda za linearno ali polinomsko prileganje; minimizira vsoto kvadratov odstopanj (residualov) med opazovanimi vrednostmi in napovedanimi vrednostmi modela.
- Polinomsko prileganje — uporaba polinomov različnih stopenj; preprosto za uporabo, vendar lahko vodi do oscilacij (Rungejev pojav) pri visokih stopnjah.
- Interpolacijske metode — npr. Lagrangeova interpolacija, Newtonova interpolacija ali linearna interpolacija; zagotovijo točno prileganje skozi vse točke (brez napak), primerne, kadar so meritve zanesljive in želimo natančno rekonstrukcijo med točkami.
- Razdeljene (piecewise) polinomske metode in kubični spline — podatke prilegajo s kosnimi polinomi, ki so zglajeni na vozliščih; kubični B-spline ali naravni spline so pogosti, saj nudijo dobro ravnotežje med prilagodljivostjo in gladkostjo.
- Glajenje (smoothing) — npr. gladilni spline, Savitzky–Golay filter; cilj je odstraniti šum in poudariti osnovni trend brez natančnega prileganja vsaki točki.
- LOESS / LOWESS — lokalno uteženo regresijo, ki prilagodi preproste modele (npr. linearne) na lokalnih podmnožicah podatkov; uporabna pri neparametričnih glajenjih.
- Kernel regresija — način neparametričnega glajenja, ki uporablja jedra (kernel) za uteževanje sosednjih opazovanj.
- Regularizirane metode — ridge (L2), lasso (L1) in elastic net zmanjšujejo kompleksnost modela in preprečujejo preveliko prileganje z dodajanjem kaznovalne članice v funkcijo izgube.
- Robustne metode — npr. Huberjeva regresija ali RANSAC, uporabne, kadar so v podatkih odstopanja (outlierji) in ne želimo, da močno vplivajo na prileganje.
Meritve kakovosti prileganja
- R² in prilagojeni R² — merita delež variance pojasnjene z modelom; prilagojeni R² upošteva število parametrov in velikost vzorca.
- RMSE (root mean squared error) in MAE (mean absolute error) — povprečne meritve napake napovedi v enotah izvornih podatkov.
- AIC, BIC — kriteriji za primerjavo modelov, ki upoštevajo primerjalno kakovost fit-a in število parametrov (manjše je bolje).
- Preverjanje preostalih vrednosti (residual diagnostics) — grafi residualov, preverjanje normalnosti, homoskedastičnosti in avtokorelacije pomagajo oceniti primernost izbranega modela.
- Križna validacija (cross-validation) — npr. k-fold CV za oceno sposobnosti modela, da generalizira na nove podatke in za izbiro hiperparametrov (kot sta stopnja polinoma ali parameter glajenja).
Past in previdnost
- Preveliko prileganje (overfitting) — model se preveč prilega šumu v učnih podatkih; kaže se kot zelo dobra natančnost na učnih podatkih, vendar slaba na novih podatkih.
- Premalo prileganje (underfitting) — model je preveč preprost, da bi zajel strukturo podatkov; napake ostajajo velike tudi na učnih podatkih.
- Ekstrapolacija — kot je že omenjeno v uvodu, je uporaba prilagojenih krivulj zunaj območja opazovanih podatkov tvegana; napovedi izven razpona vhodnih podatkov pogosto niso zanesljive in so močno odvisne od izbranega modela.
- Odvisnost od meril in predpostavk — rezultati prilagajanja so odvisni od izbrane funkcijske družine, uteževanja opazovanj, predobdelave (npr. skaliranje) in morebitnih predpostavk (npr. neodvisnost napak, normalnost).
Praktični nasveti
- Začnite z enostavnimi modeli (npr. linearna regresija) in postopoma povečujte kompleksnost, če to podpirajo podatki in diagnostični pregledi.
- Uporabljajte vizualizacije (grafi s točkami in prilagojenimi krivuljami, ploti residualov) za oceno primernosti modela.
- Normalizirajte ali centrirajte spremenljivke, kadar uporabljate metode, občutljive na skalo (npr. regularizacija, nekatere spline implementacije).
- Uporabljajte križno validacijo za izbiro hiperparametrov in za oceno splošne zmogljivosti modela.
- Preverite vpliv posameznih točk (influential points) in po potrebi uporabite robustne metode ali očistite podatke.
- Če želite kvantificirati negotovost v napovedih, uporabite metode kot so bonferronijevi intervali, bootstrap ali statistikne metode, ki nudijo intervale zaupanja za napovedi.
Uporaba v praksi
- V naravoslovju in inženirstvu za modeliranje eksperimentalnih podatkov in identifikacijo zakonitosti (npr. termodinamične krivulje, odzivni modeli).
- V ekonomiji in financah za modeliranje trendov in napovedovanje (npr. gibanje cen, povpraševanje).
- V biostatistiki in epidemiologiji za modeliranje odvisnosti med spremenljivkami in napovedovanje tveganj.
- V strojni inteligenci in strojništvu za predprocesiranje, feature engineering in modeliranje nelinearnih odnosov (npr. kot del večjih modelov).
Programsko orodje
- R: funkcije kot so lm(), glm(), smooth.spline(), loess(), gam() in paketi kot mgcv, splines.
- Python: numpy.polyfit, scipy.interpolate (interp1d, splrep/splev), sklearn (linear_model, Ridge, Lasso), statsmodels za naprednejše regresijske analize.
- MATLAB: funkcije za polinomsko prileganje, spline in robustno regresijo; ima tudi grafične pripomočke za vizualizacijo.
- Orodja za vizualizacijo (ggplot2 v R, matplotlib/seaborn v Pythonu) olajšajo pregled in diagnostiko prileganja.
Zaključek: Prilagajanje krivulje je osnovno orodje za analizo podatkov, kombinira matematične metode in statistične pristope. Pravilna uporaba zahteva pozornost do izbire metode, diagnostike modela in previdnosti pri ekstrapolaciji. Z razumevanjem prednosti in omejitev posameznih metod lahko dosežemo zanesljive in uporabne rezultate.

Vprašanja in odgovori
V: Kaj je prilagajanje krivulje?
O: Prilagajanje krivulje je postopek oblikovanja matematične funkcije, ki najbolje ustreza nizu podatkovnih točk.
V: Kateri sta dve vrsti prilagajanja krivulje?
O: Dve vrsti prilagajanja krivulje sta interpolacija in glajenje.
V: Kaj je interpolacija?
O: Interpolacija je vrsta prilagajanja krivulje, ki zahteva natančno prileganje podatkom.
V: Kaj je glajenje?
O: Glajenje je vrsta prilagajanja krivulje, ki konstruira "gladko" funkcijo, ki se približno prilega podatkom.
V: Kaj je regresijska analiza?
O: Regresijska analiza je sorodna tema, ki se osredotoča na vprašanja statističnega sklepanja, na primer koliko negotovosti je prisotne v krivulji, ki se prilega podatkom, opazovanim z naključnimi napakami.
V: Katere so nekatere uporabe prilegajočih se krivulj?
O: Prilagojene krivulje lahko uporabimo za lažjo vizualizacijo podatkov, ugibanje vrednosti funkcije, kadar ni podatkov, in povzemanje odnosov med dvema ali več spremenljivkami.
V: Kaj je ekstrapolacija?
O: Ekstrapolacija je uporaba prilagojene krivulje zunaj območja opazovanih podatkov. Vendar je to predmet določene negotovosti, saj lahko odraža tako metodo, uporabljeno za konstruiranje krivulje, kot tudi opazovane podatke.
Sorodni članki
Avtor
AlegsaOnline.com Prilagajanje krivulje: definicija, metode in uporaba v statistiki Leandro Alegsa
URL: https://sl.alegsaonline.com/art/24757
Viri
- books.google.com : The Signal and the Noise
- books.google.com : Data Preparation for Data Mining
- books.google.com : pg 69