Zipfov zakon: razlaga, primeri in uporaba v jezikoslovju in analizah
Zipfov zakon: jasna razlaga, primeri in uporaba v jezikoslovju ter podatkovnih analizah — kako frekvence besed oblikujejo jezike, modele in napovedi.
Zipfov zakon je empirični zakon, oblikovan s pomočjo matematične statistike, poimenovan po jezikoslovcu Georgeu Kingsleyju Zipfu, ki ga je prvi predlagal.
Zipfov zakon pravi, da je pri velikem vzorcu uporabljenih besed pogostost katere koli besede obratno sorazmerna z njenim položajem v frekvenčni tabeli. Tako je pogostost besede n sorazmerna z 1/n.
Tako se bo najpogostejša beseda pojavljala približno dvakrat pogosteje kot druga najpogostejša beseda, trikrat pogosteje kot tretja najpogostejša beseda itd. Na primer, v enem od vzorcev besed v angleškem jeziku predstavlja najpogostejša beseda "the" skoraj 7 % vseh besed (69.971 od nekaj več kot 1 milijona). V skladu z Zipfovim zakonom je na drugem mestu beseda "of", ki predstavlja nekaj več kot 3,5 % besed (36 411 pojavitev), sledi ji beseda "and" (28 852 pojavitev). Za polovico besed v velikem vzorcu je potrebnih le približno 135 besed.
Enako razmerje se pojavlja pri številnih drugih lestvicah, ki niso povezane z jezikom, na primer pri razvrstitvi mest po številu prebivalcev v različnih državah, velikosti korporacij, dohodku itd. Felix Auerbach je leta 1913 prvič opazil pojav porazdelitve na lestvicah mest po številu prebivalcev.
Ni znano, zakaj Zipfov zakon velja za večino jezikov.
Galerija slik
3 Slike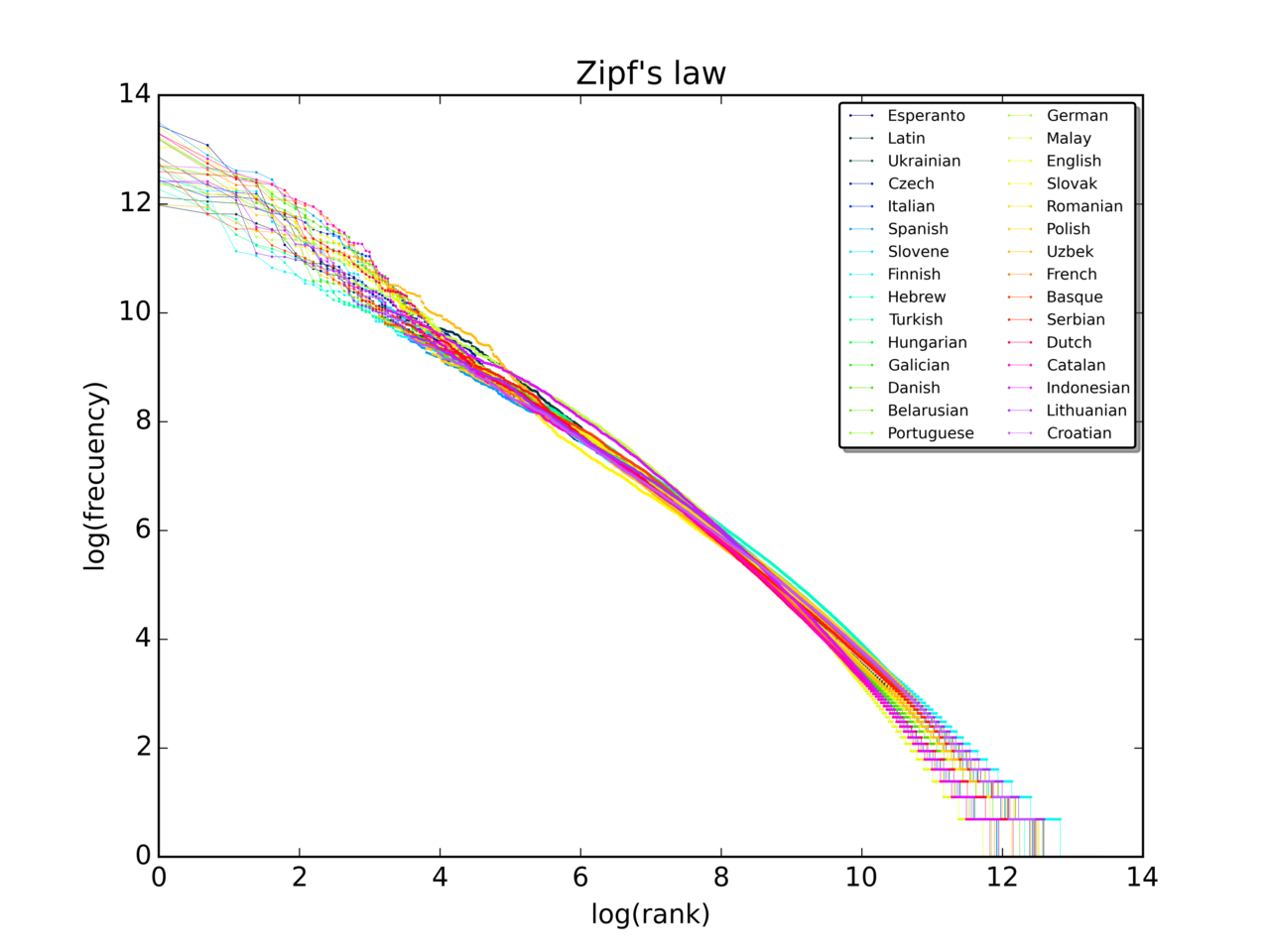


Matematična oblika in razlaga
Zipfov zakon se pogosto zapiše v obliki močne zakonitosti (power law): f(r) ∝ 1 / r^s, kjer je f(r) frekvenca besede z ranga r, in eksponent s približno en (s ≈ 1) za mnoge naravne jezike. V praksi se uporablja tudi širši model Zipf–Mandelbrot: f(r) ∝ 1 / (r + q)^s, kjer konstanta q popravlja odstopanja pri nizkih rangih (najpogostejše besede).
Na log-log grafu (log frekvence proti log ranga) Zipfov zakon daje približno ravno črto s kotom −s; za klasičen Zipfov zakon je naklon približno −1.
Zakaj se pojavi? Glavne razlage
- Princip najmanjšega napora: Zipf je sam predlagal, da govorci in poslušalci optimizirajo komunikacijo — govorci izbirajo krajše/splošnejše besede, poslušalci pa potrebujejo dovolj razločnosti, kar vodi do ravnotežja v porazdelitvi frekvenc.
- Preferenčna pritrjevanje (Simonov model): besede, ki so že pogoste, imajo večjo verjetnost ponovnega pojavljanja — proces rasti, ki daje power-law porazdelitve.
- Informacijski in kompresijski razlogi: omejena kapaciteta prenosa informacij lahko favorizira porazdelitve, kjer nekaj simbolov prevladuje, kar je izkoriščeno tudi v algoritmih stiskanja podatkov.
- Slučajni procesi in vzorčenje: nekateri preprosti naključni tekstovni modeli lahko tudi reproducirajo približno Zipfovo porazdelitev, čeprav popolna razlaga še ni enotna.
Primeri in opazovanja
Poleg besed v jeziku se podobna porazdelitev pojavi pri:
- velikostih mest (mesto prvega ranga veliko večje od drugih),
- porazdelitvah dohodkov in premoženja (sorodna Pareto porazdelitev),
- pogostosti uporabe spletnih strani, velikostih podjetij, popularnosti knjig/glasbe ipd.
Omejitve in odstopanja
- Pri zelo velikih korpusih se pojavijo odstopanja v obeh repih porazdelitve: zelo pogoste besede (členi, vezniki) pogosto odstopajo zaradi jezikovne funkcije, medtem ko na repu prevladujejo hapax legomena (besede, ki se pojavijo le enkrat).
- Različni jeziki in žanri (znanstveni članki, novice, pogovorni jezik) kažejo različne vrednosti eksponenta s, zato zipfov zakon ni absolutno enak za vse primere.
- Neprimerna uporaba linearne regresije na preurejenih log-log podatkih lahko vodi v pristranske ocene eksponenta — priporočljivi so sodobni statistični pristopi (maksimalna verjetnost, Kolmogorov–Smirnov test).
Praktične uporabe v jezikoslovju in analizi podatkov
- Modeliranje jezika: razumevanje frekvenčne strukture pomaga pri izbiri soglasnih modelov za jezikovno obdelavo (n-grami, jezikovni modeli).
- Obdelava naravnega jezika (NLP): Zipfove lastnosti vplivajo na izbiro metod za tokenizacijo, izravnavo redkosti besed (smoothing) in izbiro reprezentacij (subword, byte-pair encoding).
- Iskanje informacij in indeksiranje: pogoste funkcijske besede imajo nizko informativno vrednost (stop-words), kar vpliva na tehtanje izrazov v iskalnikih (TF–IDF ipd.).
- Analiza korpusov in stilometrija: razlike v porazdelitvah besed lahko pomagajo pri prepoznavanju avtorja, žanra ali prevoda.
- Stiskanje podatkov: ker so nekatere besede zelo pogoste, kodirni sistemi (npr. Huffmanovo kodiranje) izkoristijo nesimetrično porazdelitev za učinkovito stiskanje.
Kako testirati Zipfovo zakonitost v korpusu
Najpogostejši koraki:
- izračun frekvenc vseh oblik (tokenov),
- razvrstitev po frekvenci in dodelitev ranga,
- log-log prikaz frekvence proti rangu (za vizualno oceno),
- ocena parametrov s pomočjo metode maksimalne verjetnosti za discrete power-law ter preverjanje prileganja s Kolmogorov–Smirnov testom ali bootstrap metodami.
Povezave z drugimi zakonitostmi
Zipfov zakon je povezan z Heapsovim zakonom, ki opisuje rast slovarja z velikostjo korpusa: velikost besedišča V(N) običajno raste kot V(N) ∝ N^β (β med 0.4 in 0.6 za naravne jezike). Obstajajo tudi povezave s Pareto porazdelitvijo (v ekonomiji) in s splošno teorijo power-law pojavov v kompleksnih sistemih.
Zaključek
Zipfov zakon je močna empirična opažanja o porazdelitvi frekvenc v jeziku in drugih sistemih. Čeprav nima enotne teoretične razlage, kombinacija jezikovnih, statističnih in dinamičnih modelov pojasni številne njegove vidike. V praksi je uporaben za razumevanje frekvenčnih vzorcev, oblikovanje jezikovnih modelov in optimizacijo algoritmov v NLP, informacijskem iskanju in analizi podatkov.
Vprašanja in odgovori
V: Kaj je Zipfov zakon?
O: Zipfov zakon je empirični zakon, ki pravi, da je pogostost besede v velikem vzorcu obratno sorazmerna z njenim položajem v frekvenčni tabeli.
V: Kdo je predlagal Zipfov zakon?
O: Zipfov zakon je prvi predlagal jezikoslovec George Kingsley Zipf.
V: Kako Zipfov zakon pojasnjuje pogostost besed v vzorcu angleških besed?
O: Po Zipfovem zakonu se najpogostejša beseda v vzorcu angleških besed pojavi približno dvakrat pogosteje kot druga najpogostejša beseda, trikrat pogosteje kot tretja najpogostejša beseda itd. Ta trend se nadaljuje z zmanjševanjem ranga besede.
V: Kolikšen odstotek vseh besed predstavlja najpogostejša beseda v vzorcu angleških besed?
O: V nekem vzorcu angleških besed najpogostejša beseda ("the") predstavlja skoraj 7 % vseh besed.
V: Kakšno je razmerje med številom besed, potrebnih za polovico vzorca, in pogostostjo teh besed?
O: V skladu z Zipfovim zakonom je za polovico besed v velikem vzorcu potrebnih le približno 135 besed.
V: Za katere druge lestvice velja Zipfov zakon?
O: Enako razmerje, kot ga Zipfov zakon opisuje pri pogostosti besed, se pojavlja tudi pri drugih lestvicah, ki niso povezane z jezikom, na primer pri razvrstitvi prebivalstva mest v različnih državah, velikosti korporacij in dohodkovnih lestvicah.
V: Kdo je opazil pojav porazdelitve na lestvicah mest po številu prebivalcev?
O: Felix Auerbach je leta 1913 prvi opazil pojav porazdelitve na lestvicah mest glede na število prebivalcev.
Sorodni članki
Avtor
AlegsaOnline.com Zipfov zakon: razlaga, primeri in uporaba v jezikoslovju in analizah Leandro Alegsa
URL: https://sl.alegsaonline.com/art/110649
Viri
- books.google.com : P. 139